The Factors That Shape the Web
Can Blockchain Technology Replace the Ranking System Behind Search Engines?

Now, I’m no blockchain nor SEO expert. And I know these two concepts just sound like buzzwords. But from my humble understanding of these technologies, I feel like there’s enough overlap here for some good innovation (as a lightweight thought experiment).
Google’s Been Shaping the Web
Something that’s always bugged me about search ever since I learned about the original "semantic web" idea, was that the keywords and factors that make things rank are pretty much a property of the search engine. Which tend to be private companies. This sets the tone for what a webpage should contain if it is to show up in search contexts. The practice of SEO sends to the world a bunch of very specific requirements from how your title should be written, what words need to show up how many times in your writing, and how much scrolling needs to happen before getting to the recipe. (Yes, that's why recipe webpages always start with a lengthy personal story about someone's grandmother and her famous yellow mixer that inspired the way the dish is plated.)
Search Has Become an Industry
The other main problem I see with centralized search is that it’s become an industry. Companies of all sizes need some sort of SEO expert on their team to even hope to make it in the current market. Also the fact that you can simply pay to show up on any query results page. You can pay your way out of needing SEO, which is deplorable. Because if I’m going online looking for something specific, I want to reach that thing, not waste decision energy scrolling past paid results. (At least the Sponsored mention is obligatory, thank GOD —although more and more subtle.)
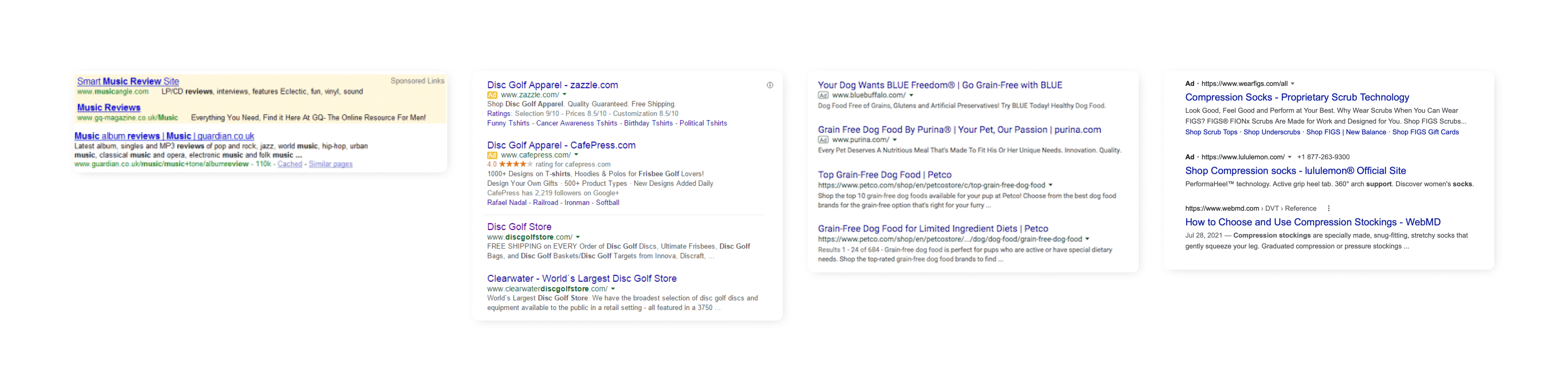
Behaviour as Commodity
There’s also the concern of privacy. How your search behaviour is being tracked and probably sold. I simply loathe that I have to be very calculated in what I search for (at least in non-private browsing mode) because of the threat of getting targeted ads and knowing my data has been manipulated against my will.
Google’s big thing is how over time, it has accumulated such precise data about us that we get a "better experience" but what’s better? Getting results based on past behaviour? Or getting stuff that semantically matches what you input?
The Attraction (And Limits) Of Purely Semantic Search
I’ve always wondered just how efficient a purely semantic search experience would be. Of course, I understand you’d need to input much more specific queries, and this means you would have to know in advance what you’re looking for. Which again is a habit we kind of lost because of the existing search algorithms. But a purely semantic search is the most neutral. It might not be the most useful or helpful, but it is simply accurate. If you searched for "pottery experiment", you'd get everything that matches with that string almost one-to-one. It would take into account the number of times that very term is mentioned on the page itself, how many other websites are pointing to that webpage (backlinks, references) and how many people actually end up on that page after doing the same query.
Now, having 1:1 results based on your query is pretty limiting. The search engine isn’t helping you finish your sentence, or suggesting related searches. It’s not giving you much. That’s when we realize the importance of metadata —or keywords. They play a huge part in bringing nuance to the semantic meaning of a result. Keywords add depth and layers to, say, the title that is trying to get matched to a search query.
But keywords ended up being managed by the Googles of this world and are QA’ed and documented by people from a private company. This centralization is pretty bad for the Web’s health. This centralization means that if your side project or the webpage you’re working on doesn’t have SEO settings, you’re likely never going to show up on Google at all. And we all know Google pretty much powers the world’s entry point to the Internet. It’s the default engine behind many browser tab bars, it’s integrated in our voice assistants, it’s what many of us default to to navigate the physical world around us.
What About the Blockchain?
Comes in this idea of the blockchain. A highly secure, distributed, continuously audited log of entries. A system that, in my mind, could act wonderfully at gathering and maintaining user-generated keywords for search engines. What I love about the blockchain is that by definition, it cannot be controlled by a single agent. That alone is, to me, at the core of what the Web needs.
"The system had to have one other fundamental property: It had to be completely decentralized. That would be the only way a new person somewhere could start to use it without asking for access from anyone else. And that would be the only way the system could scale, so that as more people used it, it wouldn't get bogged down."
—Tim Berners-Lee, Weaving the Web
Ledger Record as Metadata
Instead of being a transaction, a record in the ledger could be made of the webpage’s permalink, the page title, the hierarchy of headings, the thumbnail image link, the sitemap, and a series of keywords. And the transaction part of it would be to compare the previous record to the new one being proposed by whomever was last on that page, wanting to contribute changes.
Browser Integration
I’m imagining an in-browser integration where anyone and everyone could upvote various webpages, submit semantic keywords, review entries from others, dispute keywords, confirm if images are present, confirm that the article is actually about what it says in the title.
Fighting Google’s Biases
Some of the factors I would want to see removed from search engines is how many people visited the link. This is a super biased metric in that it can happen so easily by accident. If a certain link happens to have the right keywords to rank for a given search, it’ll be clicked on a couple times. But if it turns out not being super relevant, and people spend an insignificant amount of time on the page, it still registers the opens. Hence, it’ll rank more and continue to be clicked on a lot of times. And this continues exponentially until it reaches, by accident, the top of the first page.
On our modern, complex and increasingly recursive environment:
"Recursive here means that the world in which we live has an increasing number of feedback loops, causing events to be the cause of more events (say, people buy a book because other people bought it), thus generating snowballs and arbitrary and unpredictable planet-wide winner-take-all effects."
—Nassim Nicholas Taleb, The Black Swan
Also, isn’t it just super intrusive that those clicks we make, often mindlessly, are being registered, that the time we spend on a page is being recorded, that where our mouse hovers is being tracked. And by a private company who’s raison d’être is to sell ads. I just think that is such a shame. I feel the Internet could be so much more.
For Us, by Us
With something like blockchain-based SEO, we could be the ones telling the Internet what it is. The metadata would come from human brains —since the actual data is to be searched for and found by human brains. Not algorithms.
But then I wonder who would be our Satoshi here. Who’s the one, or the team that would determine the new SEO criteria, the ranking factors to look out for? The —pretty dismal— reality is we’d probably start by mimicking the current model since we don’t really know what else is possible yet. Or we could start very lean and have only a few data points. And the system could be made so that it scales and contributors could easily propose and vote on new fields that would become requirements for all webpage entries. (Although you can't edit records on the blockchain, only append...)
But then if anyone can propose new requirements, how do we regulate that? Having a centralized body for decision-making would totally break the purpose here. And having requests need to be audited by a certain amount of people could become a lengthy process and risks demotivating people from doing it at all. What would the consensus process be? Obviously I don't have answers here, but I like mapping out the whole picture to make an opinion for myself.
Transparency
What’s fun about the blockchain option is how transparent it is. Anyone who’s tech-savvy enough could easily consult that webpage’s record and inspect its current state. And I’m even thinking if this gets properly integrated in browsers, this doesn’t even have to be so technical, it could be easily done by anyone. It could become a core part of how we use the Internet and expect to navigate webpages. There could be a comprehensive UI for it. We could even, at the search engine level, turn on and off certain global variables, so that we could tweak our own version of the engine and intentionally decide not to base our search on specific aspects like presence of images, or number of visits. How amazing would that be?
Downsides of De-marketing the Web
Just like BBSE’s (blockchain-based search engines), a blockchain based SEO system would not support Internet marketing. Which is a double-edged sword. As much as I want that for big brands, removing their power of monopoly, I'm a big believer in the creator economy, and the Internet being this never-before-seen enabler of one-person companies. But de-marketing the Internet has impacts on brands of all sizes and I wonder how that would impact independent creators.
Hopefully, it could somehow encourage the real ones, and reduce the propagation of social media influencers that are living breathing ads. I’m all for creators who actually create new things and bring authentic value to the world, but influencers who are managed by marketing agencies and do product placement for a living, I’m sorry but they are yet another disease of the Internet.
If we go all out here, we can even think of a reward system and make this into a coin. (This is very close to the limit of my understanding of the blockchain but let's go for it!) Maybe in the contribution process, there’s some unique identifier that can act as a proof-of-contribution, or a proof-that-one-has-verfified-this-metadata-makes-sense-for-this-specific-webpage. And that could yield monetary rewards. So instead of Google making money, or paid links profiting from targeted traffic, WE could cash in on this system. Oh how the tables would turn…

I'm fully aware that I haven't covered nearly all the aspects to consider. Ranking is only part of the picture. For a search engine to even work, there are massive crawling and indexing efforts that need to happen as well. And they surely have whole sets of technical constraints that deserve their own evaluation of how we might decentralize them.